API Models
Overview
Bodhi App supports hybrid AI architecture - use powerful API models from leading providers alongside your local GGUF models in a unified interface.
Key Features:
- OpenAI API format support, more API format support in pipeline
- Multi-provider support providing API in OpenAI format, e.g. OpenAI, OpenRouter, Huggingface Inference APIs
- Access to variety of models from the supported providers (Anthropic, Groq, Mistral, Perplexity, Qwen etc.)
- Encrypted API key storage (AES-GCM)
- Model discovery from provider APIs
- Prefix-based routing for namespace separation
- Test connection before saving
- Seamless switching between local and remote models
Why Use API Models?
Advantages:
- Access latest frontier models (GPT-5, Claude Sonnet 4.5, Grok via cloud)
- No local GPU required
- Instant availability (no downloads)
- Automatic model updates from providers
- Pay-per-use pricing
When to Use Local vs Remote:
- Local: Privacy-sensitive data, offline access, no usage costs
- Remote: Latest capabilities, specialized tasks, no hardware limits
Supported API Formats and Providers
API Format: Bodhi App currently supports the OpenAI API format for remote model providers.
How Providers Work: A provider is defined by the combination of:
- API Format: The API specification (currently OpenAI format only)
- Base URL: The endpoint URL that identifies which provider service you're connecting to
Tested Providers (all using OpenAI API format):
- OpenAI
- OpenRouter
- HuggingFace Inference API
Custom Providers: Any provider that implements the OpenAI-compatible API format can be configured by manually entering its base URL and API key.
Available Models: When you configure a provider, Bodhi App fetches all currently available models from that provider. Only added models will be available for chat completion or embedding requests.
Getting Started with Common Providers
All providers listed below use the OpenAI API format. Configure them by selecting the OpenAI format and entering the appropriate base URL:
-
OpenAI
- API Format: OpenAI
- Base URL:
https://api.openai.com/v1 - Get API key from OpenAI Platform
-
OpenRouter
- API Format: OpenAI (compatible)
- Base URL:
https://openrouter.ai/api/v1 - Get API key from OpenRouter dashboard
-
HuggingFace Inference API
- API Format: OpenAI (compatible)
- Base URL:
https://router.huggingface.co/v1 - Get API key from HuggingFace settings
-
Custom Provider
- API Format: OpenAI (compatible)
- Base URL: Provider-specific endpoint
- Requirements: Provider must implement OpenAI-compatible API format
- Manually configure base URL + API key as provided by your custom provider
Creating an API Model
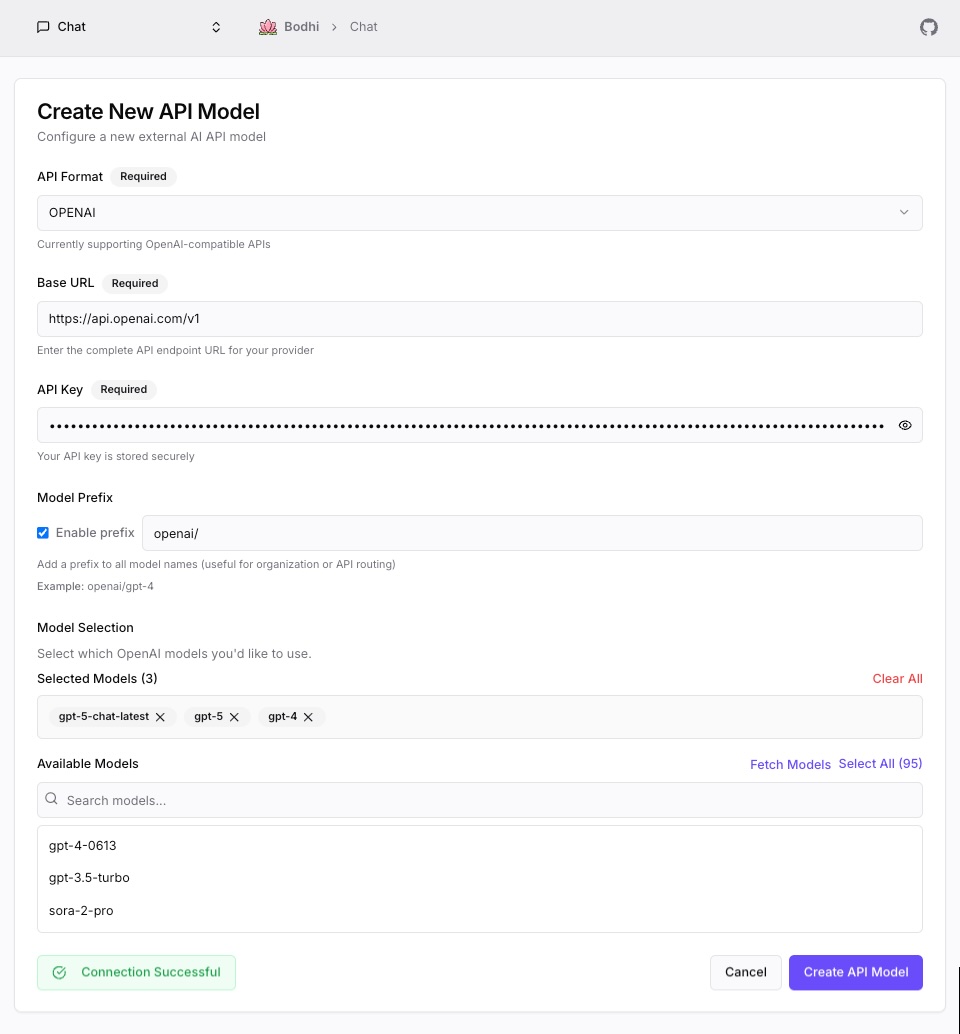
Step 1: Navigate to API Models Page
From Models Page:
- Go to Models page (/ui/models/)
- Click "New API Model" button
From Setup Wizard (optional step):
- During setup, on API Models step
- Click "Configure API Model"
Step 2: Select API Format and Configure Provider
Configure which provider you want to connect to by selecting the API format and entering the base URL.
-
Select API Format: Click the "API format" dropdown and select the format
- Currently only OpenAI format is supported
- Future support planned for Anthropic, Grok, and other API formats
-
Enter Base URL: The provider is determined by the base URL you enter
- For OpenAI: The form auto-fills
https://api.openai.com/v1 - For OpenRouter: Enter
https://openrouter.ai/api/v1 - For HuggingFace: Enter
https://router.huggingface.co/v1 - For other OpenAI-compatible providers: Enter their specific base URL
- For OpenAI: The form auto-fills
Base URL Requirements:
- Must be a complete endpoint URL
- Should end with the path to which
/chat/completionscan be appended - Example: For OpenAI, the base URL is
https://api.openai.com/v1, so chat completions endpoint becomeshttps://api.openai.com/v1/chat/completions
Technical Specifications: For API implementation details, see OpenAPI Documentation.
Step 3: Enter API Key
Your API key is encrypted before storage using AES-GCM encryption.
- Enter API key in password field
- Key is masked for security
- Enter your API key from the provider (presence validated only, no format restrictions)
Security:
- API keys encrypted with AES-GCM before database storage
- De-crypted everytime from DB and sent to the provider when forwarding the request
Step 4: Configure Model Prefix (Optional)
Model prefixes enable namespace separation and explicit provider routing when using multiple providers.
What is Prefix Routing?
Provider resolution happens based on the model field in the request. Prefixes allow you to explicitly control which provider handles the request, especially when multiple providers offer the same models.
Real-World Example: Both OpenAI and OpenRouter can provide access to GPT-4. Using prefixes lets you choose which provider to use:
-
Without prefix (OpenAI direct):
- Model ID:
gpt-4 - Routes to: OpenAI provider (direct API)
- Model ID:
-
With prefix
openai/(OpenAI explicit):- Configure OpenAI with prefix:
openai/ - Model ID:
openai/gpt-4 - Routes to: OpenAI provider (useful when you have multiple OpenAI configs)
- Configure OpenAI with prefix:
Steps:
- Toggle "Enable Prefix" switch
- Enter prefix using provider identifier (e.g.,
openai/,openrouter/,hf/) - Prefix should be alphanumeric with a few allowed symbols, no spaces (maximum 32 characters)
- All models from this provider will use the prefix
When to Use Prefixes:
- Multiple providers offer access to the same models (e.g., both OpenAI and OpenRouter provide GPT-4)
- You want explicit control over which provider handles the request
- You need clear provider identification in the model list
- Organizing models by source/provider
When NOT to Use Prefixes:
- You only configure one provider
- Each provider offers unique models with no name conflicts
Trade-offs:
- With prefix enabled, you must include it in model IDs when using Bodhi App's API
- Example:
openai/gpt-4instead ofgpt-4
Step 5: Fetch Available Models
Discover which models are available from your API provider.
- Click "Fetch Models" button
- Bodhi App queries provider's
/v1/modelsendpoint - Model list appears in dropdown
- Models are sorted by: Local models first, then grouped by provider, alphabetically within each group
If Fetch Fails:
- Verify API key is correct
- Check base URL is accurate
- Ensure network connectivity
- Review error message for specific issue
Step 6: Select Models
Choose which models to make available in Bodhi App.
- Click "Models" dropdown (multi-select)
- Select one or more models
- Selected models shown as chips
- Model Limit: Maximum of 50 models per API provider
Model Selection Tips:
- Select models for different use cases (fast, capable, specialized)
- Models can be added or removed after API model creation using the Edit function
Step 7: Test Connection (Recommended)
Validate configuration before saving to catch errors early.
- Click "Test Connection" button
- Bodhi App sends test request to provider
- Success or error message displayed
- For new models, the test uses the API key entered in the form. For existing API models, it uses the stored API key. The test makes a small chat completion request with retry logic.
Test Success: Configuration is valid, proceed to save
Test Failure Common Reasons:
- Network failure is the most common connection failure reason
- API key invalidity might also cause failure
- Verify API key is correct
- Check base URL is accurate
- Ensure network connectivity
Step 8: Save Configuration
- Click "Create" or "Save" button
- Configuration saved to database (API key encrypted)
- Redirected to Models page
- API models appear in unified model list
Using Remote Models in Chat
Once configured, remote models appear alongside local models in chat.
Steps:
- Open Chat page (/ui/chat/)
- Open Settings panel (right sidebar)
- Click "Model" dropdown
- Type in the model name selected in API model form
- Chat with remote model as usual
Visual Indicators:
- Remote models are grouped by API provider in the model selector
- Models are grouped by the API provider and have the prefix if configured for easy identification
Managing API Models
Editing API Models
Update configuration, change API key, or modify model selection.
Steps:
- Go to Models page (/ui/models/)
- Locate API model in table
- Click "Edit" button in Actions column
- Modify fields as needed
- API key shows placeholder (for security)
- To update the API key, enter a new one in the field
- Re-fetch models if needed
- Test connection
- Save changes
Editing Capabilities:
- Update base URL
- Change API key (enter new key to update)
- Modify prefix
- Add or remove models (models can be added/removed after API model creation)
Deleting API Models
Remove API model configuration when no longer needed.
Steps:
- Go to Models page
- Locate API model
- Click "Delete" button
- Confirm deletion
- API model removed
Effects:
- Configuration deleted from database
- API key removed from storage
- Models no longer available in chat
- Existing chats using this model are preserved but cannot be continued (continuation may return an error)
Viewing API Models
API models appear in unified Models page alongside local aliases.
Display:
- For API Model, action column shows top 3 available models from provider, clicking on it takes you to Chat UI with model preselected
- When multiple models from one provider: models are grouped by the API provider for easy selection
- API Format column shows API format
- File/Endpoint column shows Base URL configured
- Source badge: API models show "☁️ API" badge, local models show "model" badge
Hybrid Usage Patterns
Cost Optimization
Combine local and remote models based on task:
Free (Local):
- Drafting and ideation
- Simple questions
- Privacy-sensitive queries
- High-volume tasks
- Offline scenarios
Paid (Remote):
- Final output generation
- Complex reasoning
- Specialized tasks (coding, analysis)
- Latest capabilities
- Maximum quality requirements
Privacy Strategy
Local for Sensitive Data:
- Personal information
- Proprietary code
- Confidential documents
- Medical or financial data
- Any data you cannot share externally
Remote for Public Knowledge:
- General questions
- Public information queries
- Learning and exploration
- Creative writing
- Standard coding tasks
Performance Strategy
Local for Speed Control:
- You control inference speed
- Predictable performance
- No network latency
- Works offline
Remote for Maximum Performance:
- Latest hardware acceleration
- Faster inference for large models
- No local resource constraints
- Continuous improvements
Troubleshooting
API Key Invalid
Symptoms: "Invalid API key" error on test or usage
Solutions:
- Verify API key copied correctly (no extra spaces)
- Check key hasn't been revoked in provider dashboard
- Ensure key has required permissions
- Obtain API keys from your provider's dashboard - each provider has specific requirements, consult their documentation
- Generate new key if necessary
Model Fetch Fails
Symptoms: Cannot retrieve model list from provider
Solutions:
- Verify API key is valid
- Check base URL is correct (including /v1 path)
- Ensure network connectivity
- Try testing connection first
- Review error message for specific issue
Connection Test Fails
Symptoms: Test connection returns error
Common Errors:
- "Invalid API key": The API key is incorrect. Verify your API key is copied correctly from the provider
- "Network error": Unable to connect to the provider. Check your internet connection
- "Connection failed": Cannot reach the provider. Verify the base URL is correct
- "Model not found": The selected model is not available from this provider
- "Rate limit exceeded": Too many requests. Wait a moment before trying again
Solutions:
- Verify each configuration field
- Check provider service status
- Review error message details
- Ensure API key permissions are sufficient
For additional troubleshooting, see the Troubleshooting guide.
Model Not Appearing in Chat
Symptoms: API model configured but not in chat dropdown
Solutions:
- Refresh page
- Verify models were selected during configuration
- Re-save API model configuration
- Check that models are properly listed on the Models page
Chat Fails with API Model
Symptoms: Selected API model but chat returns error
Solutions:
- Verify API key is still valid
- Check provider account has credits/quota
- Test connection in API Models page
- Check error message for specific issue
- Ensure the model is still available from the provider
Unexpected Costs
Prevention:
- Monitor usage in provider dashboards
- Set spending limits in provider accounts
- Use local models for high-volume tasks
- Review model pricing before selection
- Track costs per provider monthly
Token Usage Tracking:
Currently not available. Token usage tracking is a planned feature for future releases.
Workaround: Check your provider's dashboard for token usage and billing information.
Security Best Practices
API Key Management
Storage:
- Bodhi App encrypts keys with AES-GCM
- Never commit keys to version control
- Don't share keys in plaintext
- Use environment variables for scripts
API Key Updates:
- No automatic key rotation
- Update keys manually anytime via the Edit API Model page
- Enter new key and click "Test Connection" to verify
- Changes take effect immediately
Key Rotation Process:
- Create new key in provider dashboard
- Update in Bodhi App using Edit API Model
- Test with new key to verify it works
- Delete old key from provider after confirming new key works
Permissions:
- Grant minimum required permissions
- Obtain API keys from your provider's dashboard - each provider has specific requirements, consult their documentation
- Review key permissions regularly
- Revoke unused keys
Access Control
Bodhi App Permissions:
- Only authorized users can configure API models
- API keys are encrypted and cannot be viewed after creation
- Keys are securely stored and never displayed in plain text
Monitoring
Track Usage:
- Review provider usage dashboards
- Set up spending alerts in provider accounts
- Monitor for unexpected spikes in your provider's dashboard
Token Usage Tracking: Currently not available in Bodhi App. Check your provider's dashboard for detailed usage information.
Provider-Specific Notes
Bodhi App supports OpenAI API-compatible providers. Below are notes for tested providers:
OpenAI
Available Models:
- All current OpenAI models are fetched dynamically when you add the provider
- Models include GPT-4, GPT-3.5 Turbo variants, and other offerings
- Refer to OpenAI's pricing page for latest model availability
Considerations:
- Rate limits vary by tier
- Batch API available for bulk processing
- Function calling supported
- Check OpenAI Pricing for current rates
OpenRouter
Available Models:
- All current OpenRouter models are fetched dynamically when you add the provider
- OpenRouter provides access to multiple AI providers through a single API
- Prefix feature is optional, similar to OpenRouter's own prefix system
Considerations:
- Aggregates models from multiple providers
- Pricing varies by model - check OpenRouter dashboard
- Good option for accessing multiple providers with one API key
HuggingFace Inference API
Available Models:
- All current HuggingFace Inference API models are fetched dynamically when you add the provider
- Wide variety of open-source models available
- Model availability depends on HuggingFace hosting
Considerations:
- Open-source model ecosystem
- Pricing and availability vary by model
- Check HuggingFace documentation for model-specific details
Other Providers
Future Support: Support planned for Anthropic, Grok, and other AI API formats in future releases.
Custom Providers: Any OpenAI-compatible API can be configured using the Custom provider option. For technical API specifications, see OpenAPI Documentation.
Related Documentation
- Model Aliases (Local) - Local GGUF models
- Chat Interface - Using models in chat
- API Tokens - Programmatic access
- Setup Wizard - First-time setup
- Models Page - Unified model view