Chat UI
Welcome to Bodhi App's Chat UI! This guide is designed to help you get started with our conversational AI interface. Whether you are a first-time user or someone looking to explore advanced configuration options, you will find all the information you need in this guide.
Overview
Bodhi App's Chat UI features a clean, three-panel design that keeps everything you need at your fingertips. The interface is divided into:
- Chat History Panel (Left): View and manage your past conversations.
- Main Chat Panel (Center): Interact directly with the AI assistant.
- Settings Panel (Right): Configure the AI's behavior using various parameters.
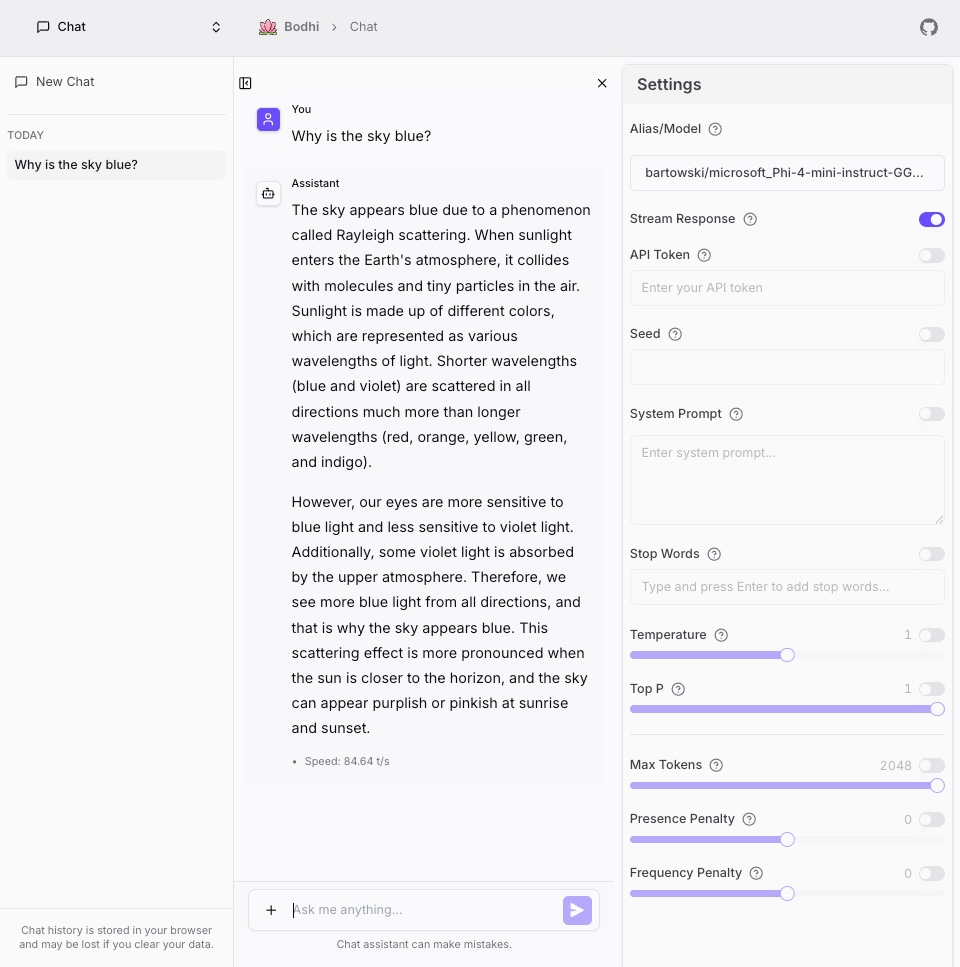
Every conversation and setting is stored locally in your browser. This means your data is private but will be lost if you clear your browser data.
Streaming Responses
Bodhi App uses real-time streaming to display AI responses as they are generated, providing a more interactive and responsive experience.
How It Works:
- When you send a message, your message appears immediately in the chat
- The AI assistant's response streams token-by-token as it's generated
- Typing indicators are not currently shown during streaming responses
- You can watch the response build in real-time instead of waiting for completion
Stop Generation:
- Currently option is not available to stop streaming mid-way
- You can navigate away from the page to drop the network connection, this will only drop the update to the page
- The request will still be processed till complete in the backend
- Having the request processing stopped once the connection is dropped, or stopped explicitly by user is in works
Technical Details:
- Uses Server-Sent Events (SSE) for real-time streaming
- Responses are saved to LocalStorage as they complete
Benefits:
- Faster perceived response time (see output immediately)
- Better user experience (no blank waiting screen)
- Can stop long or irrelevant responses early
- More natural conversation flow
The Chat History Panel
The left panel displays your previous conversations grouped by the time they were started—such as Today, Yesterday, and Previous 7 Days. You can click on any conversation to reopen it. A dedicated delete option lets you permanently remove a conversation from your browser's local storage, so use it with caution.
LocalStorage Data Structure:
- Conversations are stored in browser LocalStorage under the key
bodhi-chats - Current active chat ID is stored in
bodhi-current-chat - Sidebar state (open/closed) persists in
sidebar-history-open
Data Persistence:
- Chat history survives page reloads and browser restarts
- Storage limits depend on your browser (typically 5-10MB)
- Data is private to your browser - not sent to any server
- Chats are stored in browser localStorage for complete privacy
Clear Chat History:
- Chats are not stored on the server side - they're stored only in browser localStorage
- When you clear chat history, it deletes the chats from browser localStorage
- Your conversations stay on your device and are never sent to the server
The Main Chat Panel
The center panel is where the conversation happens. Here you can:
- Type your message in the input field at the bottom.
- Press Enter (or click the + icon) to start a new chat or submit your message.
- Enjoy real-time streaming of AI responses, or see complete responses once processing is finished.
- Experience rich content rendering: Markdown is converted to HTML, and code blocks are syntax highlighted
- Copy the response or code block using Copy button
Chat Statistics
Bodhi App displays real-time performance metrics for each AI response, helping you understand model performance and optimize your settings.
Metrics Displayed:
- Speed: Displays processing speed in tokens per second (e.g., "Speed 25.3 token/sec")
- Statistics appear below each AI message after completion
- Metrics are saved with chat history and displayed each time you view the conversation
Use Cases:
- Monitor model performance across different configurations
- Compare local vs remote model speed
- Troubleshoot slow responses or performance issues
- Understand resource consumption for different models
Statistics by Model Type:
- Local GGUF Models: Show inference speed based on hardware (CPU/GPU)
- API Models: Statistics display varies by provider and network conditions
The Settings Panel
The right panel is your command center for configuring how the AI responds. The Settings panel provides 12+ configuration parameters to fine-tune AI behavior.
Panel Controls:
- Sidebar can be collapsed to maximize chat space
- Settings are saved globally for the user in browser LocalStorage
- Settings apply to new messages and conversations
- Settings changes do not affect already completed conversations
- Each parameter has a tooltip explaining its purpose and impact
Model Selection (Required)
You must select a model before sending messages to the AI.
Available Models:
- Local Model Aliases: GGUF models you've configured on your device
- API Models: API models from providers (OpenAI, Anthropic, Groq, Together AI)
- Models are shown in a single dropdown without visual distinction between local and remote models
Model Dropdown:
- Shows all available models in a searchable dropdown
- Selecting a model enables the send button
- Switching models mid-conversation starts a new context
Temperature (0-2)
Controls randomness and creativity in responses.
Range: 0.0 to 2.0 Control Type: Slider with numeric input
Parameter Priority (highest to lowest):
- Chat UI settings (if manually configured)
- Model alias settings (if using alias)
- GGUF file defaults (if using model file directly)
Guidance:
- 0.0-0.3: Focused, deterministic output (technical tasks, factual responses)
- 0.4-0.7: Balanced creativity and coherence (general conversation)
- 0.8-1.2: Creative and varied responses (creative writing, brainstorming)
- 1.3-2.0: Highly random and experimental (artistic generation)
Max Tokens
Maximum length of the AI response in tokens.
Current Limit: Currently hard-coded to max to 2,048 tokens, leave it unchecked to use the model default Control Type: Numeric input
Guidance:
- 100-500: Short responses (quick answers, summaries)
- 500-2000: Standard responses (detailed explanations)
- 2000-4000: Long-form content (essays, articles)
- 4000-8192: Extended content (long articles, documentation)
Note: Longer responses consume more resources and take longer to generate.
Top P (Nucleus Sampling)
Alternative to temperature for controlling response diversity.
Range: 0.0 to 1.0 Control Type: Slider with numeric input
Guidance:
- 0.1-0.5: Focused responses with limited vocabulary
- 0.6-0.9: Balanced diversity
- 0.95-1.0: Full vocabulary, maximum diversity
Note: Can be used together with Temperature for fine-grained control.
Top K
Limits token selection to the top K most probable tokens.
Control Type: Numeric input
Note: Interacts with Top P and Temperature to control token selection.
Frequency Penalty
Reduces repetition by penalizing tokens based on their frequency in the text so far.
Control Type: Slider with numeric input
Effects:
- Positive values: Reduce repetition (model less likely to repeat words)
- Negative values: Encourage repetition
- Zero: No frequency penalty applied
Presence Penalty
Reduces repetition by penalizing tokens that have already appeared.
Control Type: Slider with numeric input
Note: Works differently from Frequency Penalty - penalizes any token that appeared, regardless of how often.
Stop Sequences
Custom sequences that stop response generation when encountered.
Control Type: Tag-based input
- Press Enter to create a stop sequence badge
- Click on a badge to remove it
- Add multiple stop sequences as needed
Examples:
\n\n- Stop at double newline (paragraph breaks)###- Stop at specific markerHuman:- Stop before conversation turn
Use Cases:
- Structured output generation
- Preventing over-generation
System Prompt
Sets instructions or context for the AI assistant.
Format: Multi-line text input Character Limit: No limit Storage: Saved in browser LocalStorage as a global user setting
Examples:
You are a helpful coding assistant specialized in Python.
Provide concise code examples with explanations.
Respond concisely in 2-3 sentences maximum.
Use simple language appropriate for beginners.
You are a creative writing assistant.
Help users brainstorm ideas and develop compelling narratives.
Tips:
- Be specific about desired behavior
- Include output format instructions if needed
- Test different prompts to find what works best
API Token
API token for authenticated requests.
Use Case: Enter an API token to test authenticated access to Bodhi App APIs
- Alternative to session-based authentication
- Useful for testing API token functionality
- Token-based access to chat completions
Storage: Stored in LocalStorage for convenience
Note: API tokens grant access to Bodhi App features. Keep them secure and remove after testing.
Parameter Controls
Toggle Switches:
- Each parameter has an enable/disable toggle
- When disabled, the backend default value is used
- This allows testing different configurations without manual reset
Settings Persistence:
- Settings persist globally in LocalStorage
- Settings apply to all new messages and conversations
- Sidebar state (open/closed) saved in
sidebar-settings-open
Understanding Sampling Parameters
Bodhi App uses llama.cpp as its inference engine. All sampling parameters (Temperature, Top P, Top K, Frequency Penalty, Presence Penalty) are passed directly to llama.cpp for processing.
Parameter Interaction:
- These parameters can be used together and interact in complex ways
- Different models may respond differently to the same parameter values
- Experimentation is key to finding optimal settings for your use case
For Technical Details: See llama.cpp documentation for in-depth information on parameter ranges, defaults, and interactions.
Reference Configurations
For advanced users, here are sample configurations for common use cases:
Creative Writing:
Temperature: 0.8
Top P: 0.9
Presence Penalty: 0.6
Frequency Penalty: 0.3
Max Tokens: 2048
Technical Responses:
Temperature: 0.2
Top P: 1.0
Presence Penalty: 0.1
Frequency Penalty: 0.1
Max Tokens: 1024
Balanced Conversation:
Temperature: 0.5
Top P: 1.0
Presence Penalty: 0.4
Frequency Penalty: 0.4
Max Tokens: 1500
Collapsible Panels & Starting a New Chat
Both the Chat History and Settings Panels are collapsible. This allows you to maximize your workspace if you have limited screen space or wish to focus solely on your conversation. You can toggle each panel independently.
Panel State Persistence:
- Left sidebar (history): Stored in
sidebar-history-openLocalStorage key - Right sidebar (settings): Stored in
sidebar-settings-openLocalStorage key - Panel states persist across page reloads and browser sessions
You have two options to start a new conversation:
- Click the + button in the main chat input area.
- Use the new chat option in the Chat History Panel.
New Chat Behavior:
- Clears current conversation context
- Retains your selected model and settings
- LocalStorage entry is created when the first message is sent
Error Handling
Bodhi App includes robust error handling to ensure a smooth chat experience.
Input Restoration:
- If an error occurs before streaming starts, your input is restored to the text field
- You can edit and retry your message without retyping
- Simply press Enter to resend
Error Display:
- Errors are shown in a toast notification at the bottom right of the screen
- The message remains in your input field so you can retry
- Partial responses (if streaming was interrupted) are stored with error state
Common Errors:
- "Network connection failed": Check your internet connection and try again
- "Model unavailable": The selected model may be loading or unavailable. Try a different model or wait a moment
- "Request timeout": The request took too long. Try with a shorter prompt or different model
- "Rate limit exceeded": Too many requests in a short time. Please wait a moment before trying again
Mobile and Responsive Design
The Chat UI adapts to different screen sizes for optimal experience on all devices.
Responsive Behavior:
- Mobile: Sidebars become drawer overlays, single-column chat layout, simplified settings panel
- Tablet: Collapsible sidebars adapt to available space
- Desktop: Fixed dual sidebars with optional collapse, full settings panel with all controls visible
The interface automatically adjusts based on your screen size to provide the best experience.
Advanced Features
Copy Functionality:
- Copy entire messages with copy button
- Copy individual code blocks
- Visual feedback indicates successful copy
Markdown Rendering:
- Rich text formatting (bold, italic, lists, headings)
- Code blocks with syntax highlighting for common programming languages
- Tables and blockquotes
- Clean, readable formatting in light and dark themes
Code Highlighting:
- Automatic language detection for code blocks
- Syntax highlighting adapts to your selected theme
- Copy button on all code blocks for easy code reuse
Related Documentation
- Model Aliases - Configure local GGUF models
- API Models - Set up API providers
- API Tokens - Create tokens for programmatic access
- Application Settings - System configuration
Final Thoughts
Bodhi App's Chat UI is thoughtfully designed to combine ease of use with powerful functionality. With real-time streaming, comprehensive performance statistics, and 12+ configuration parameters, you have complete control over your AI conversations.
Key Highlights:
- Real-time streaming responses for immediate feedback
- Comprehensive settings panel with 12+ parameters
- Performance statistics to monitor and optimize
- Local data storage for privacy and persistence
- Support for both local GGUF and API models
- Rich markdown rendering and code syntax highlighting
- Responsive design for mobile, tablet, and desktop
Enjoy interacting with the AI assistant and experiment with the settings to tailor the experience to your needs. Always remember that your configurations and history are stored locally in your browser, so manage your data wisely.
Happy chatting!